前言
在深度学习领域,一份好的数据决定了成功的一半。为了得到优质的声音样本,我特意选取了三位相声大师的单口相声,音频样本简单纯粹,每一位都选取了十分钟以上的音频信息。将音频信息安装停顿切成一个个不超过10s的小声音片段,然后对每一段音频进行MFCC特征提取,获得数百个带标签的音频样本。
MFCC简介
MFCCs(Mel Frequency Cepstral Coefficents)是一种在自动语音和说话人识别中广泛使用的特征。它是在1980年由Davis和Mermelstein提出。
在任意一个Automatic speech recognition 系统中,第一步就是提取特征,把音频信号中具有辨识性的成分提取出来,然后把其他的无关的信息丢弃,例如背景噪声、情绪等等。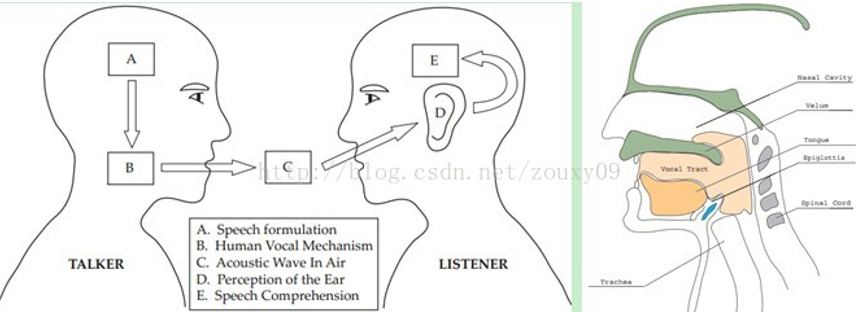
搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的构造决定了发出怎样的声音。声道的构造包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素进行准确的描述。声道的构造在语音短时功率谱的包络中显示出来。而MFCCs就是一种准确描述这个包络的一种特征。
传统方法对一段音频信号进行倒谱分析,提取频谱包络(连接所有共振峰值的包络),但是,对于人类听觉感知的实验表明,人类听觉的感知只聚焦在某些特定的区域,而不是整个频谱包络。
而Mel频率分析就是基于人类听觉感知实验的。实验观测发现人耳就像一个滤波器组一样,它只关注某些特定的频率分量(人的听觉对频率是有选择性的)。也就说,它只让某些频率的信号通过,而压根就直接无视它不想感知的某些频率信号。但是这些滤波器在频率坐标轴上却不是统一分布的,在低频区域有很多的滤波器,他们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏。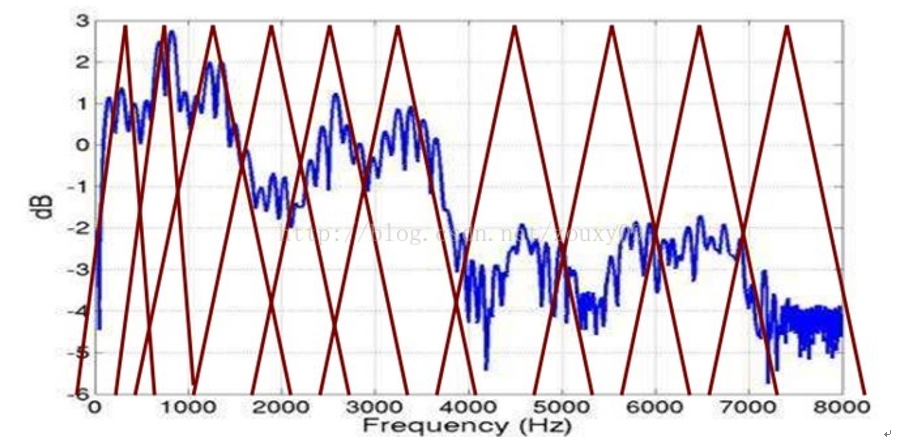
人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的。在语音特征的提取上,人类听觉系统做得非常好,它不仅能提取出语义信息, 而且能提取出说话人的个人特征,这些都是现有的语音识别系统所望尘莫及的。如果在语音识别系统中能模拟人类听觉感知处理特点,就有可能提高语音的识别率。
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。将普通频率转化到Mel频率的公式是:
由下图可以看到,它可以将不统一的频率转化为统一的频率,也就是统一的滤波器组。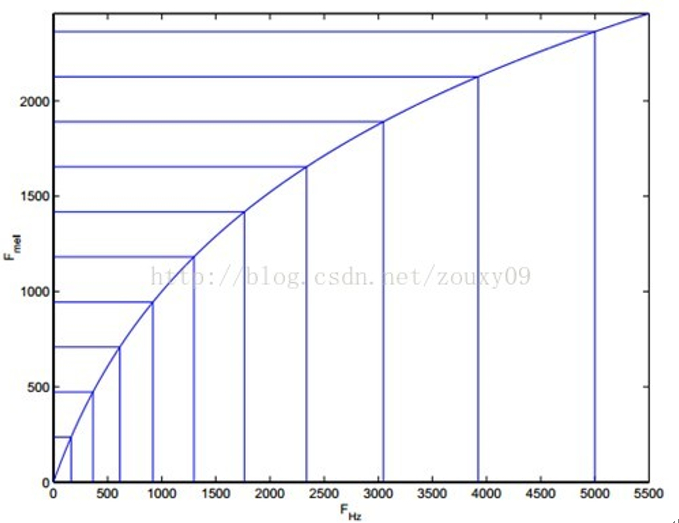
在Mel频域内,人对音调的感知度为线性关系。举例来说,如果两段语音的Mel频率相差两倍,则人耳听起来两者的音调也相差两倍。
我们将频谱通过一组Mel滤波器就得到Mel频谱。公式表述就是:
这时候我们在$log X[k]$上进行倒谱分析:
1)取对数:$logX\left[k\right]=logH\left[k\right]+logE\left[k\right]$
2)进行逆变换:$x\left[k\right]=h\left[k\right]+e\left[k\right]$。
在Mel频谱上面获得的倒谱系数$h\left[k\right]$就称为Mel频率倒谱系数,简称MFCC。
参考文献
[1] https://blog.csdn.net/zouxy09/article/details/9156785zouxy09@qq.com
[2] https://www.ilovematlab.cn/thread-295269-1-1.html
[3] https://blog.csdn.net/watfe/article/details/80284242
